Value-Based 와 Policy-Based RL
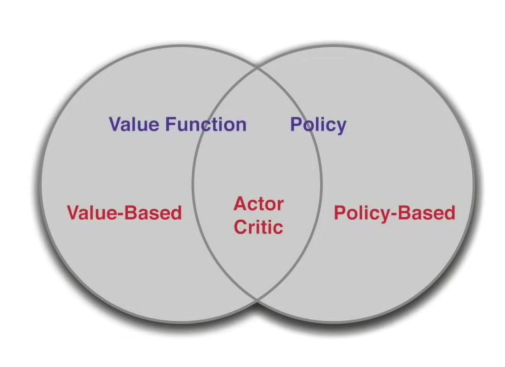
Value-based, Policy-Based의 장점
- 아타리 게임과 같은 경우 한 어떤 state를 value function을 정의하는것이 힘듬
- 다른말로 해보면, 한 state space가 거의 continous -> 거의 Infinite한 경우에 대해 value function을 만들어야 하기 때문에 value function을 정의하기 힘들다 표현 한 듯
- 반대로 Policy 자체는 간편할 수 있음(그냥 왼쪽으로 가기 등)
- Q. 결과적인 Policy는 쉬워보이는데 그 학습 과정이란…?

- Q. 결과적인 Policy는 쉬워보이는데 그 학습 과정이란…?
이것이 아타리 게임
Policy-base의 장점
- 장점
- 더 잘 수렴함(convergence)
- 고차원 또는 연속 action space 에서 효율적임(0,0.001,0.002,… 의 경우를 뜻하는 듯)
- stochastic policies 학습 가능
- 단점
- global 보단 local로 수렴
- High variance
- Policy Evaluation이 비 효율적임
가위바위보 예시
stochastic Policy의 장점 설명
- Deterministic Policy
- 가위는 보자기를 이김
- 보자기는 바위를 이김
- 바위는 가위를 이김
- Deterministic을 사용 경우 쉽게 Exploit하게 됨
- 이를 역이용해 오히려 지게 된다
- 결과적으로 uniform random policy가 optimal임 (Nash equilibrium)
예시 2 : Aliased Gridworld
value-based의 단점 -> grid World가 있을때 주위를 둘러싼 state가 같은 value를 가지고 있다면 선택이 어렵게 된다 Policy-based의 장점 -> 이와 같은 상황에서 Policy-based방식은 각 state에서 취해야할 행동의 distribution(stochastic)을 생성 하기 떄문에 value-based방식의 단점을 극복 가능
- aliased의 뜻
- 여기서는 Grey부분이 대칭이기 때문에 동일 함. 이러한 경우를 aliased라고 뜻하는 것으로 보임
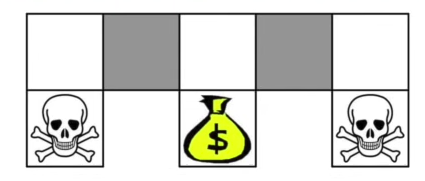 Value-based 예시
Value-based 예시
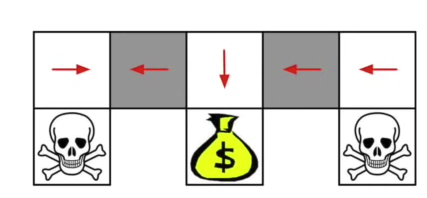 Value-based Deterministic의 단점
Value-based Deterministic의 단점
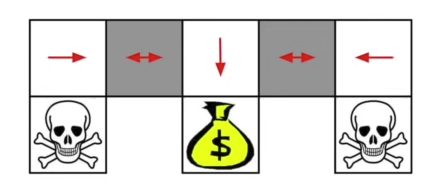 Stochastic Policy-based RL 장점
Grey 부분에서 좌우로 움직일 확률이 0.5가 되어 value-based에 비해 더 빠른 속도로 goal에 다다름
Stochastic Policy-based RL 장점
Grey 부분에서 좌우로 움직일 확률이 0.5가 되어 value-based에 비해 더 빠른 속도로 goal에 다다름
Policy Objective Function
- 목표 : Parameter 를 가진 Policy에 대해, 최적의 를 찾는 것
- 의 품질을 확인하는 방법은?
- Episodic task, start value를 사용
- Continuing, average value
- J
Study Question
- 여기 설명을 보면 Policy-based Stochastic RL의 장점을 주로 이야기하는 것으로 보임
- 그렇담 Policy-based Deterministic은 장점이 없다는 뜻인지
- 아니면 Policy-baseed 방법 자체가 Stochastic인지 이부분이 헷갈림
[1]
RL Course by David Silver - Lecture 7: Policy Gradient Methods, (2015). Accessed: Oct. 11, 2023. [Online Video]. Available: https://www.youtube.com/watch?v=KHZVXao4qXs