와우. 일단 스터디가 급해 챕터 13을 이야기 해본다. 이 챕터 전까지는 action-value method 기반이었다. 이제는 를 배울 차례. 이 친구는 value function 없이 action을 선택하는 것이다. 말이 참 애매한데, value function이 parameter를 학습시킬때는 쓰이지만 action을 선택할때는 필요가 없다. 그렇다는 것은 지도학습 모델과 조금 유사한 성격을 띄는 것으로 보인다. 아직 나도 이해가 안가지만 아무튼 계속 해보자. 그럼 지도학습처럼 본다면, weight가 필요할 것이다. 여기서는 weight라 하지않고 parameter라고 표현한다. 그걸 있어 보이게 쓰면 다음과 같다 대단히 어려워보이지만 별거 없을 것이다. 그려보면 아래와 같다.
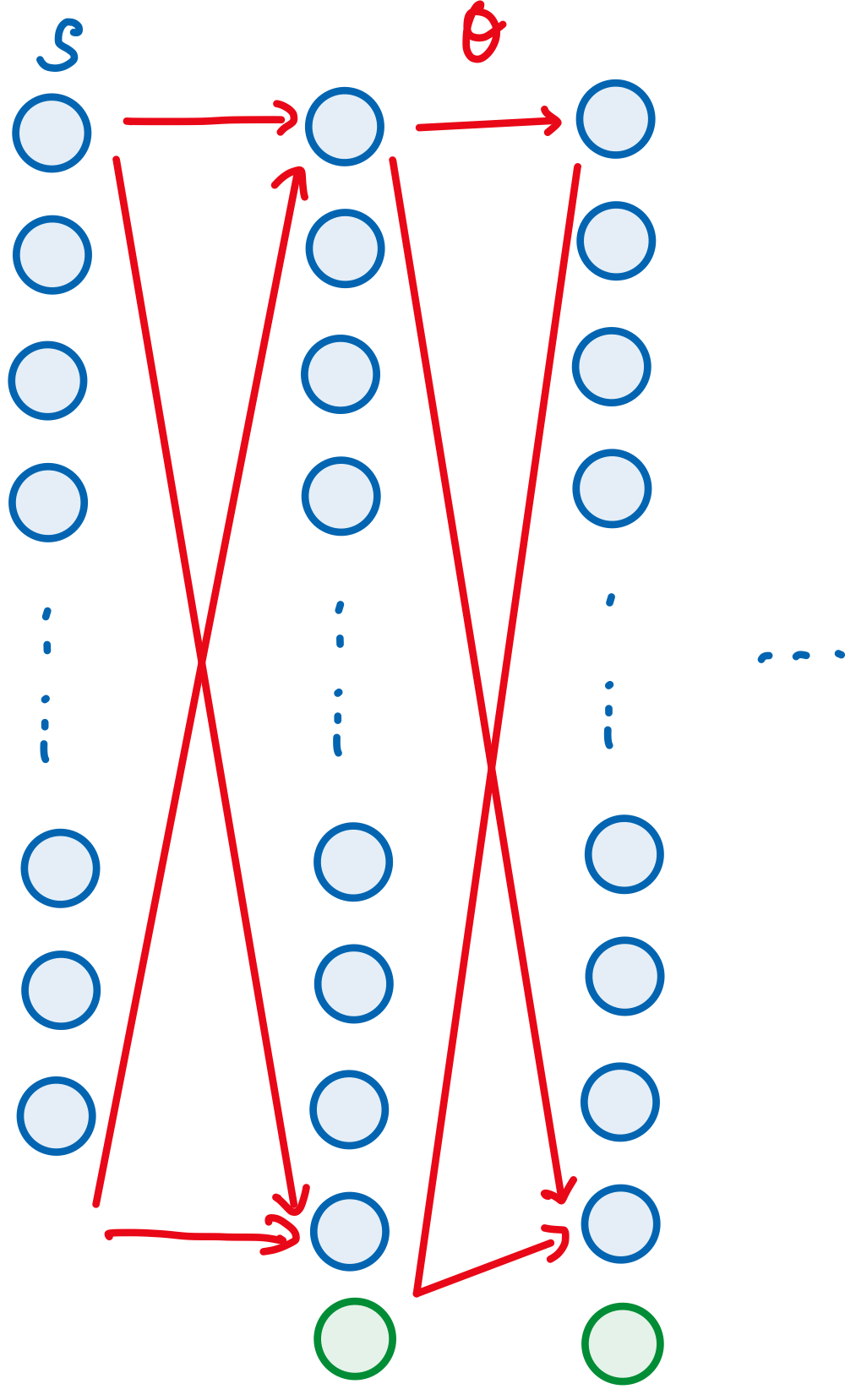
사실 누가 봐도 구분이 되지 않겠지만, 각 Layer를 이어주는 빨간선이 에 해당한다. 그럼 이제 parameter말고 parameterized policy를 써보면 아래와 같다 왼쪽 부터 읽어보면… Parameterized Policy 는 어떤 time step t에 주어진 1) State, 2)Theta에 기반해 Action a를 고를 확률 분포다. 아 참 어렵다. 앞에서 언급한 것 처럼 우리가 학습시켜야 하는 것은 다. 그렇다면 로 정의되는 성능지표를 정의한 후 해당 성능지표를 Maximize하는 방식으로 문제를 풀 수 있다. 이떄 성능지표를 라고 한다면 를 업데이트 하는 방법은 그러니까 Gradient asende를 한다 이얘기 같다. 그림으로 그려보면
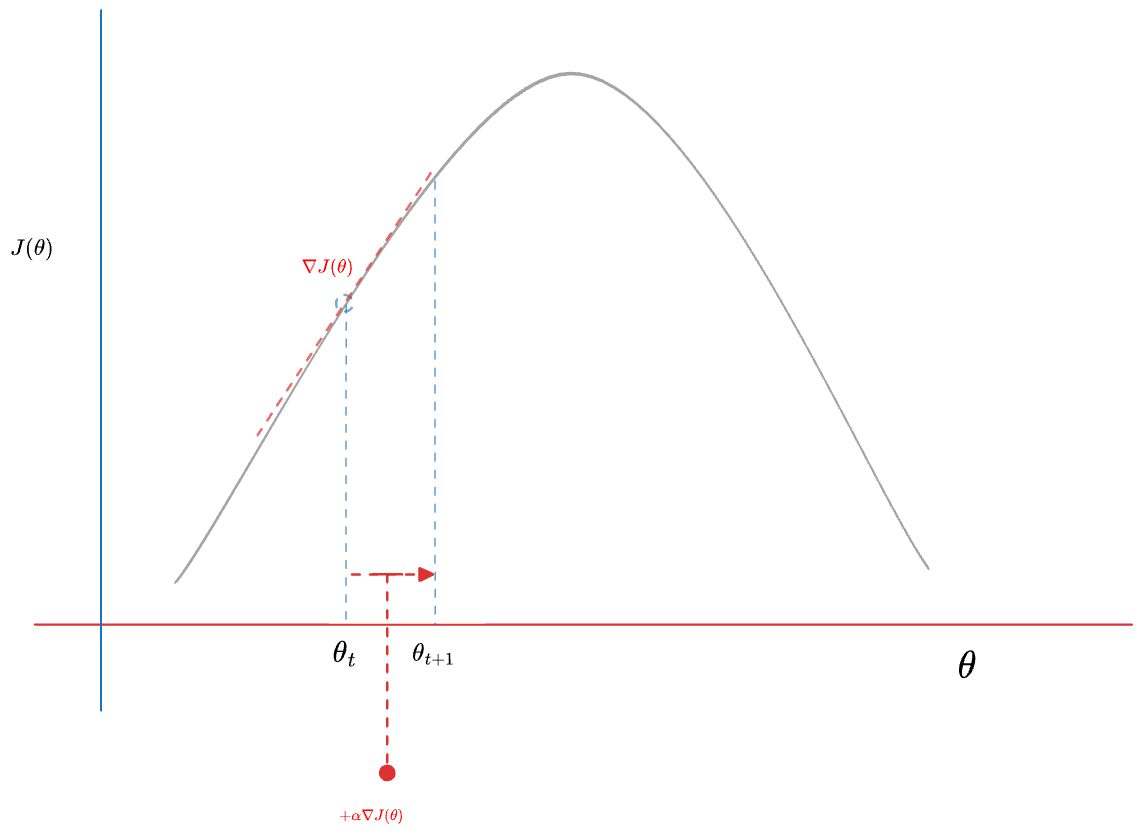 Maximization problem은 이렇게 푸는거 같더라. 위 그림을 꼬리물고 이야기하면 local optima등 좀더 복잡한 문제가 있겠지만 그건 일단 넘어가자. 그걸 얘기하려면 Newton Method 등을 얘기해야 하는데 내가 설명할 그게 안된다.
==위 식을 따르는 애들을 Policy gradient라고 한단다==. 여기까지만 해도 머리가 아프겠지만 한단계 더 나아가 보자. 여태 설명은 parameterized policy를 중심으로 이야기했다. 그말은 parameter 를 학습시키는 방법을 다뤘다. 이때 value에 대해선 크게 이야기하지 않았다. value function에 대한 추정을 같이 하는 방법을 actor-critic method라고 한다. 그리고 critic 친구는 state value를 뜻한다 그런다. 관련 이야기는 뒤에 좀더 자세히 나올테니까 일단 여기까지
Maximization problem은 이렇게 푸는거 같더라. 위 그림을 꼬리물고 이야기하면 local optima등 좀더 복잡한 문제가 있겠지만 그건 일단 넘어가자. 그걸 얘기하려면 Newton Method 등을 얘기해야 하는데 내가 설명할 그게 안된다.
==위 식을 따르는 애들을 Policy gradient라고 한단다==. 여기까지만 해도 머리가 아프겠지만 한단계 더 나아가 보자. 여태 설명은 parameterized policy를 중심으로 이야기했다. 그말은 parameter 를 학습시키는 방법을 다뤘다. 이때 value에 대해선 크게 이야기하지 않았다. value function에 대한 추정을 같이 하는 방법을 actor-critic method라고 한다. 그리고 critic 친구는 state value를 뜻한다 그런다. 관련 이야기는 뒤에 좀더 자세히 나올테니까 일단 여기까지
1 나중에 설명을 위한 섹션
Question
- action-value method를 설명하시오
- parameterized policy란 무엇인가
- ==Policy Gradient에 대해 설명하시오==