1 Policy -based methods란?
- 강화학습을 통해 찾고자 하는 것은 최적의 폴리시 다. 이 폴리시는 기대보상을 합한 값을 최대화 시킨다
- 다시 말하면 강화학습의 가설은 reward hypothesis이며, 이를 다시 풀어서 말하면 모든 문제를 풀때 목표는 기대 보상을 최대화 하는 것이라고 말할 수 있다
- 축구로 말하면 점수 획득을 최대화 하는 것 이다

2 value-based, policy-based, actor-critic method
- Unit1 - Introduction to Deep Reinforcement Learning에서 두가지 방법을 훑었지
- value-based방식은 state 또는 action의 value를 계사해 policy를 간접적으로 알아내는 방식 이었음
- 이때 target-value와 현재 값의 차이를 통해 학습하는 방식을 취함(TD-error)
- Policy-based은 value function을 구하지 않고 바로 policy를 계산하는 방법이다
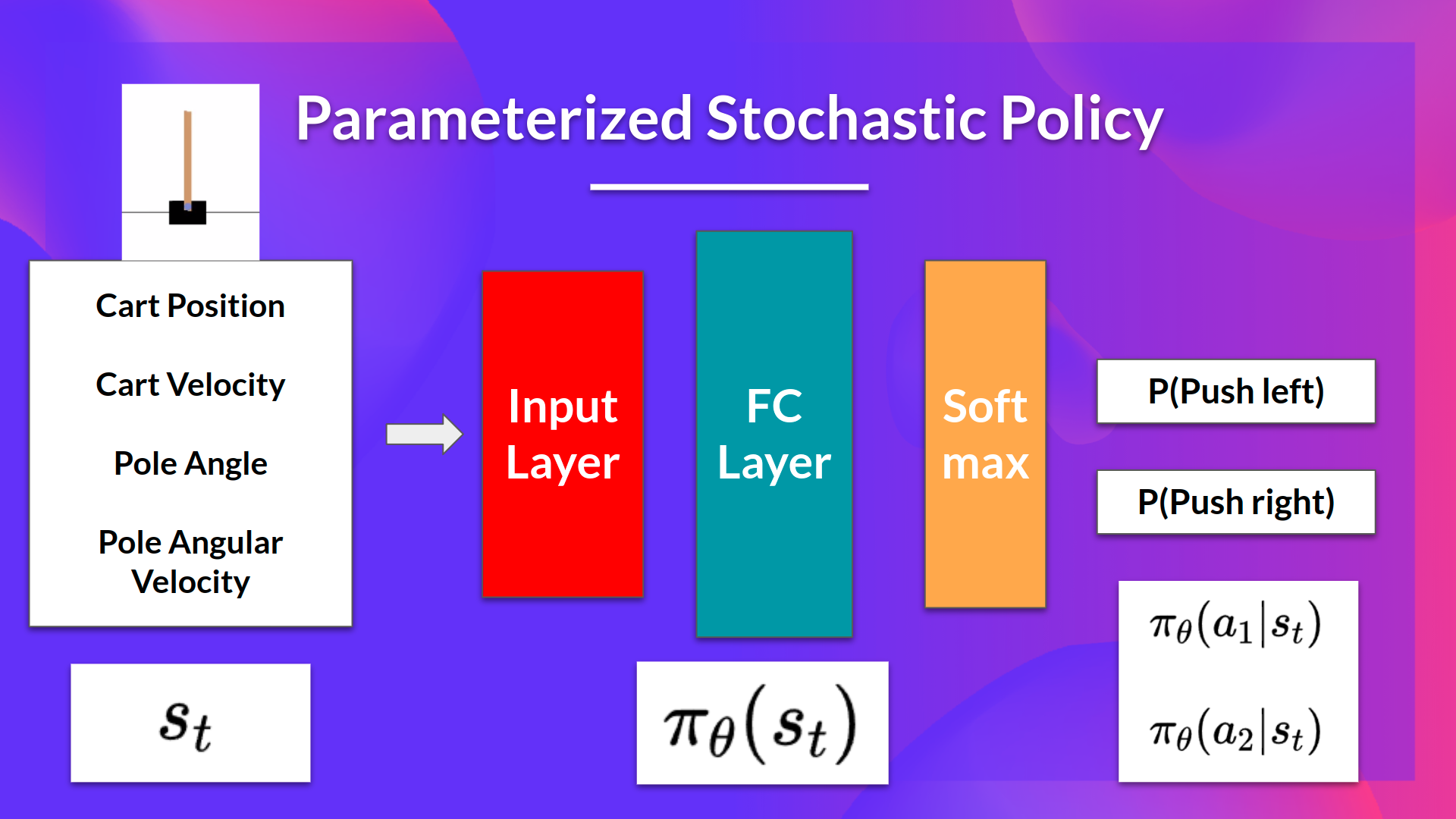
- Policy를 parameterize한대. Neural network를 이용해 를 학습시키는걸 뜻하나 보다. 이 폴리시는 어떤 행동을 취해야하는지 확률 분포를 나타내게 됨(stochastic policy)

- 라는 값을 NN을 통해 굴려보며 높은 기대성능을 보이는 를 찾는것?
- gradient ascent를 써서 성능을 최대화 하면 된다
- Actor-critic을 써서 좀더 학습해 보자
- Policy를 parameterize한대. Neural network를 이용해 를 학습시키는걸 뜻하나 보다. 이 폴리시는 어떤 행동을 취해야하는지 확률 분포를 나타내게 됨(stochastic policy)
- value-based방식은 state 또는 action의 value를 계사해 policy를 간접적으로 알아내는 방식 이었음
- Policy-based method를 이용해 값을 구할 수 있다. 이걸 하려면 를 구해야 한다. 는 목표값으로 기대보상의 합이다. 따라서 를 굴려서 를 최대화 해야한다
3 Policy-based와 Policy-gradient의 차이
- Policy-based의 하위 항목중 하나로 Policy-gradient가 존재한다
- 그래서 이 둘의 차이점을 좀 나눠보면
- Policy-based에서는 를 간접적으로 구한다고 한다
- 부분적 추정치를 가지고 하며
- 쓰는 기술도 hill climbing, simulated annealing, evolution strategies가 있다
- 반면 Policy-gradient는 를 직접 구한다.
- 방법도 gradient ascent를 쓴대
4 Policy-gradient 방식의 장단점
4.1 장점
- 간단하다(action value를 구할 필요가 없다 cf.value-based)
- Stochastic policy를 구할 수 있다
- value-based에서는 eps greedy를 썻지만 이거 자체는 deterministic policy
- Stochastic policy를 쓰기 때문에 좋은점
-
- exploration / exploitation trade-off를 신경쓰지 않아도 됨. Agent가 알아서 탐색하기 때문에 기존 경향성을 따르는 방식이 아님(value-based는 경향성을 따르게 되어 있다는 말이구나)
- Perceptual aliasing문제를 해결할 수 있다. perceptual aliasing이란 보기엔 유사하지만 다른 action을 취해야 할때를 뜻한다
- 위 상황을 예시로 알아보자

- 위 그림에서 로봇 청소기는 1) 먼지만 청소해야 하고 2) 햄스터를 청소하면 안된다(죽이면 안된다)
- 로봇청소기의 문제는 벽이 어디있는지만 인지 할 수 있다
- 그 말은 위 그림의 빨간 부분에서 로봇이 인지하는 것은 위아래 벽이 있다는 것 뿐이다
- 그렇다는 것은 deterministic policy 에서는 두 빨간 지점에서 로봇이 행할 행동이 동일하다는 것이다. 가령 왼쪽 빨간색에서 왼쪽으로 움직여야 하면 오른쪽 빨간지점에서도 왼쪽으로 움직여야 하는 것이고 반대도 마찬가지다.
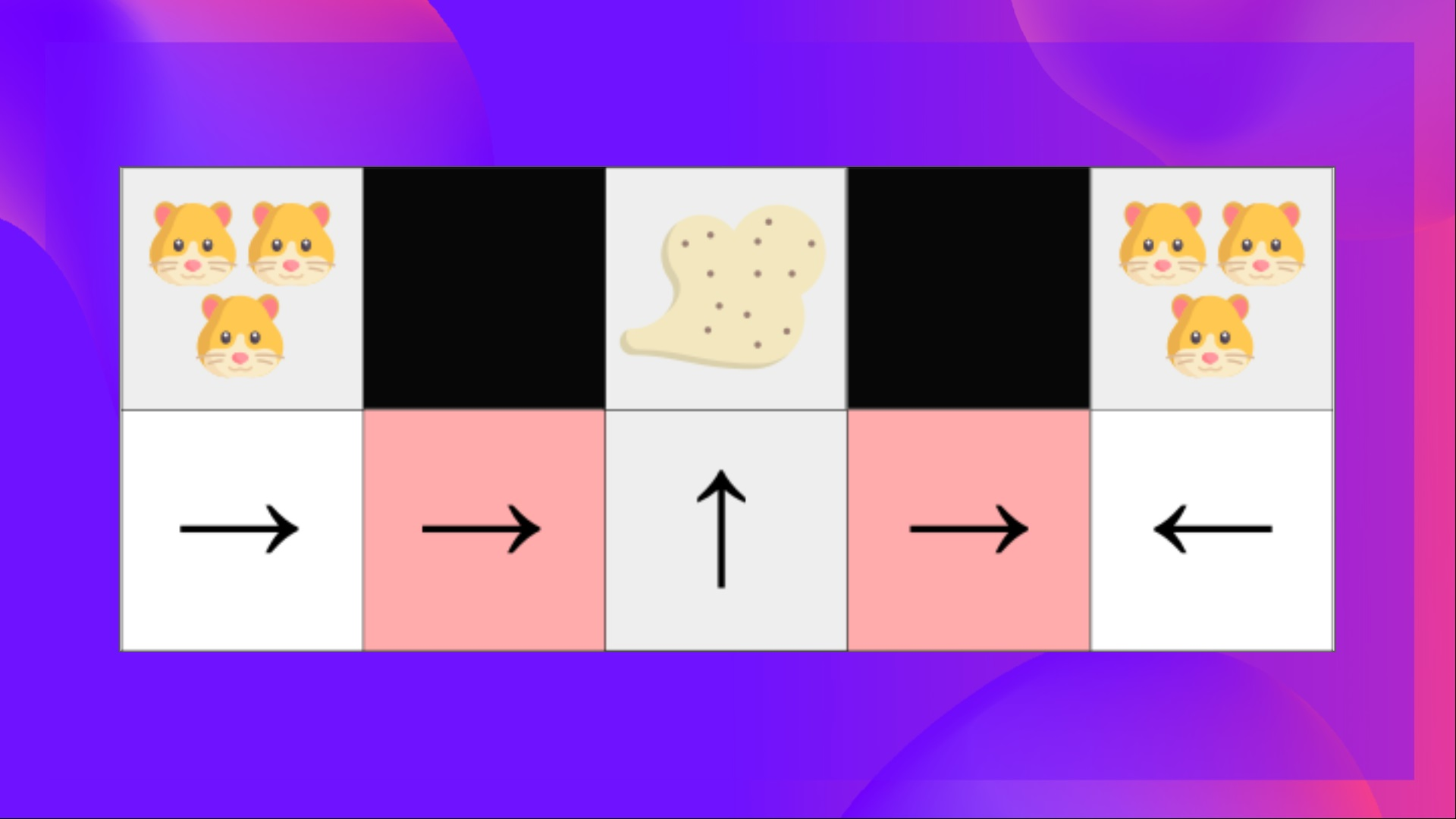
- 위 경우 먼지를 찾기 위해 시간을 많이 소비하게 된다(위 그림을 통해 보면 오른쪽 빨간지점은 와리가리를 계속하게 된다)
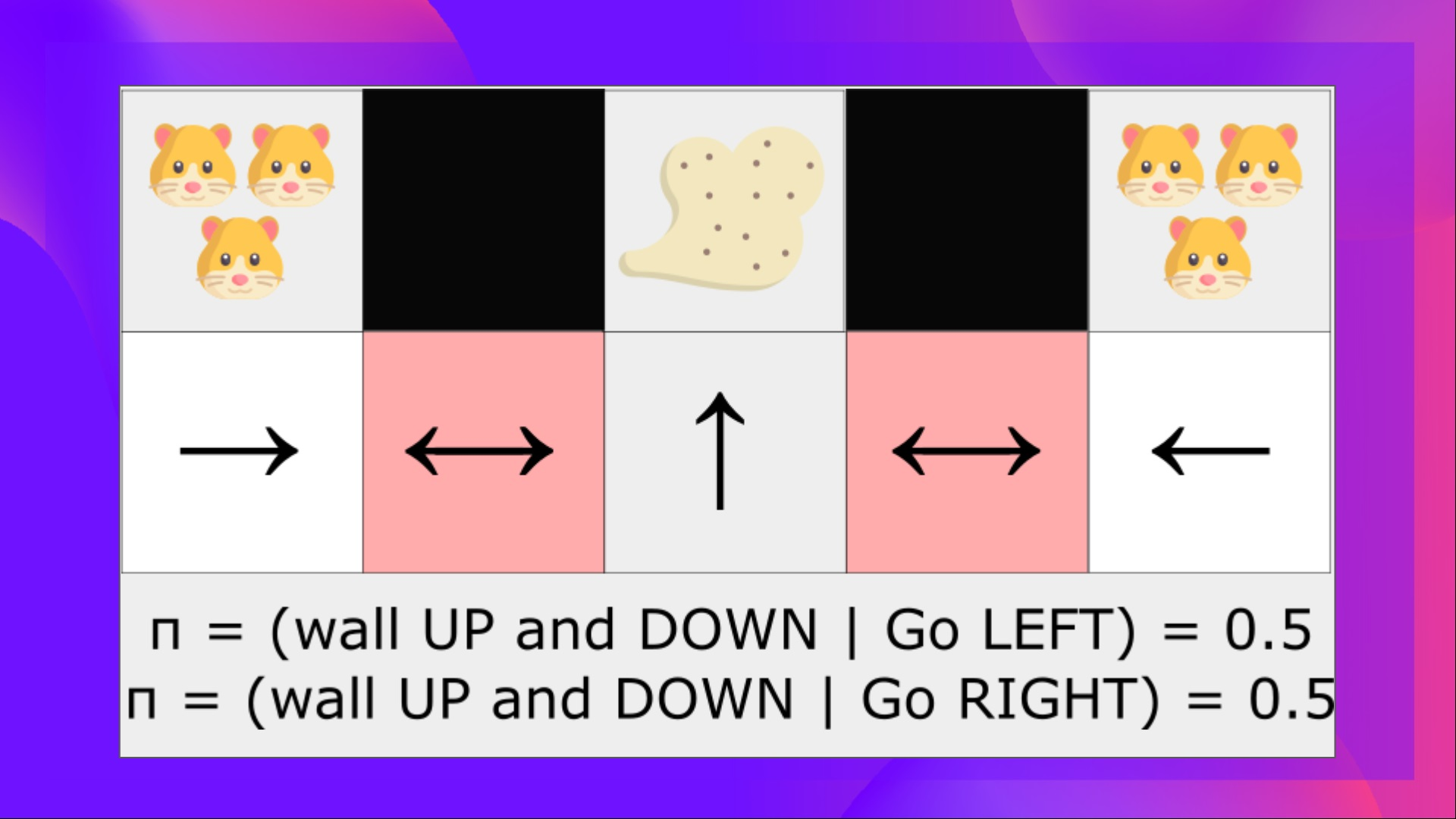
- 반면 optimal stochastic policy상에서는 해당 위치에서 왼쪽 오른쪽 이동 확률이 동일하게 될 것이고 이것은 결과적으로 해당 구간 탈출이 더 잘 될 것이다. 이 내용을 그림으로 표현하면 아래와 같다
- action space의 dimension이 높거나 continuous actions space인 경우 더 유리함
- Deep Q-learning 때는 각 action에 점수를 부여했다. 근데 거의 무한한 행동이 가능한 경우에는 힘들다
- Policy-gradient 방식이 더 잘 수렴한다
- 부드럽게 변화한다(?)
4.2 단점
- local maximum에 수렴하는 경우가 많다
- 느리다.(비효율적이다-computationally)
- high variance